Three-Hopping the Corporate Store, in Theory
Stanford University has been running a project to better understand what phone metadata can show about users, MetaPhone, in which Android users can make their metadata available for analysis.
They just published a piece that suggests we could be underestimating the intrusiveness of the government’s phone dragnet program. That’s because most assumptions about degrees of separation consider only human contacts, and not certain hub phone numbers that quickly unite us.
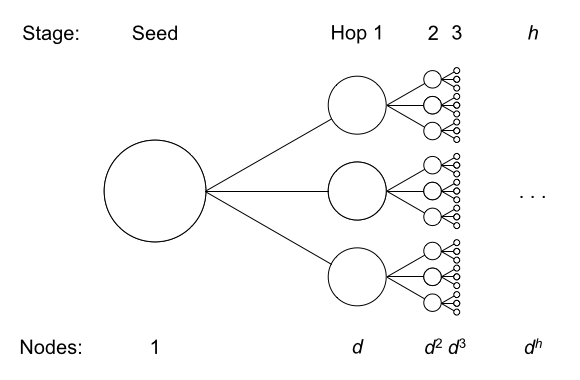
A common approach for calculating these figures has been to simply assume an average number of call relationships per phone line (“degree”), then multiply out the number of hops. If a single phone number has average degree d, and the NSA can make h hops, then a single query gives expected access to about dh complete sets of phone records.3, 4
We turned to our crowdsourced MetaPhone dataset for an empirical measurement. Given our small, scattershot, and time-limited sample of phone activity, we expected our graph to be largely disconnected. After all, just one pair from our hundreds of participants had held a call.
Surprisingly, our call graph was connected. Over 90% of participants were related in a single graph component. And within that component, participants were closely linked: on average, over 10% of participants were just 2 hops away, and over 65% of participants were 4 or fewer hops away!
In spite of the fact that just 2 of its participants had called each other, the fact that so many people had called TMobile’s voicemail number connected 17% of participants at two hops.
Already 17.5% of participants are linked. That makes intuitive sense—many Americans use T-Mobile for mobile phone service, and many call into voicemail. Now think through the magnitude of the privacy impact: T-Mobile has over 45 million subscribers in the United States. That’s potentially tens of millions of Americans connected by just two phone hops, solely because of how their carrier happens to configure voicemail.
And from this, the piece concludes that NSA could get access to a huge number of numbers with just one seed.
But our measurements are highly suggestive that many previous estimates of the NSA’s three-hop authority were conservative. Under current FISA Court orders, the NSA may be able to analyze the phone records of a sizable proportion of the United States population with just one seed number.
This analysis doesn’t account for one thing: NSA uses Data Integrity Analysts who take out high volume numbers — numbers like the TMobile voice mail number.
Here’s how the 2009 End-to-End review of the phone dragnet described their role.
As part of their Court-authorized function of ensuring BR FISA metadata is properly formatted for analysis, Data Integrity Analysts seek to identify numbers in the BR FISA metadata that are not associated with specific users, e.g., “high volume identifiers.” [Entire sentence redacted] NSA determined during the end-to-end review that the Data Integrity Analysts’ practice of populating non-user specific numbers in NSA databases had not been described to the Court.
(TS//SI//NT) For example, NSA maintains a database, [redacted] which is widely used by analysts and designed to hold identifiers, to include the types of non-user specific numbers referenced above, that, based on an analytic judgment, should not be tasked to the SIGINT system. In an effort to help minimize the risk of making incorrect associations between telephony identifiers and targets, the Data Integrity Analysts provided [redacted] included in the BR metadata to [redacted] A small number of [redacted] BR metadata numbers were stored in a file that was accessible by the BR FISA-enabled [redacted], a federated query tool that allowed approximately 200 analysts to obtain as much information as possible about a particular identifier of interest. Both [redacted] and the BR FISA-enabled [redacted] allowed analysts outside of those authorized by the Court to access the non-user specific number lists.
In January 2004, [redacted] engineers developed a “defeat list” process to identify and remove non-user specific numbers that are deemed to be of little analytic value and that strain the system’s capacity and decrease its performance. In building defeat lists, NSA identified non-user specific numbers in data acquired pursuant to the BR FISA Order as well as in data acquired pursuant to EO 12333. Since August 2008, [redacted] had also been sending all identifiers on the defeat list to the [several lines redacted].
And here’s a (heavily-redacted) training module that describes what kind of massaging the tech people (which is a wider set of people than just the Data Integrity Analysts) do with dragnet data.
If the Data Integrity Analysts operate as multiple NSA documents say they do, this kind of quick inclusion of all Americans shouldn’t happen — it’s precisely the kind of noise NSA says it is trying to defeat.
There are just two problems with this then. First, as I have noted in the past, the inclusion or exclusion of high volume numbers will at times be a judgment call, and could lead to eliminating the most valuable pieces of intelligence in the dataset if targets knowingly or unknowingly exploit these high volume numbers. Similarly, it could easily be used — and may already have been — to make the dragnets totally unusable at critical times.
More importantly, this tech role receives far less oversight than the regular analysts do. And Dianne Feinstein’s Fake FISA Fix might even eliminate some of the oversight on the position now. So we have almost no way (and Congress seems to want to deprive itself of having a way) of ensuring these Data Integrity Analysts are doing what we think they’re doing.
If NSA is doing what it says, then the Stanford analysis should be moot, because it doesn’t account for that Data Integrity role. But ACLU’s Patrick Toomey explained back in August, NSA has a very real incentive to get as much data picked up in queries and into the corporate store as it can.
All of this information, the primary order says, is dumped into something called the “corporate store.” Incredibly, the FISC imposes norestrictions on what analysts may subsequently do with the information. The FISC’s primary order contains a crucially revealing footnote stating that “the Court understands that NSA may apply the full range of SIGINT analytic tradecraft to the result of intelligence analysis queries of the collected [telephone] metadata.” In short, once a calling record is added to the corporate store, anything goes.
More troubling, if the government is combining the results of all its queries in this “corporate store,” as seems likely, then it has a massive pool of telephone data that it can analyze in any way it chooses, unmoored from the specific investigations that gave rise to the initial queries. To put it in individual terms: If, for some reason, your phone number happens to be within three hops of an NSA target, all of your calling records may be in the corporate store, and thus available for any NSA analyst to search at will.
But it’s even worse than that. The primary order prominently states that whenever the government accesses the wholesale telephone-metadata database, “an auditable record of the activity shall be generated.” It might feel fairly comforting to know that, if the government abuses its access to all Americans’ call data, it might eventually be called to account—until you read footnote 6 of the primary order, which exempts entirely the government’s use of the “corporate store” from the audit-trail requirement.
Not “defeating” numbers like the TMobile voice mail is a very easy way to populate the corporate store with very very broad swaths of US person data so as to be able to access it with much less stringent controls.
All of which demonstrates the urgency for more oversight into whether the Data Integrity Analysts are doing what they say they’re doing.
this is just extraordinary.
there can be no doubt that the nsa scientists knew this informstion with certainty. thus, the agency’s managing officials and attorneys have very seriously mislead the congress, the news media, and the citizens about the ease with which the nsa can spy on our activities.
as a recent analyst commented, more or less (don’t recall a cite):
“metadata is everything. it tells you all you need to know about a person and her relationships and movements. you don’t really need content.”
I really hope something comes up soon that will put the proverbial fork in DiFi’s Senate career.
One thing to consider with the high volume numbers is that more often than not those phone numbers connect to a voice response unit (VRU) and people enter in everything from account numbers to social security numbers or pay a bill via the phone entering the routing number and chechking account number or Visa/Matercard/Amex numbers. Those DTMF entries are sent across the lines and show up in call detail records. The NSA can use those values to cross-reference with other data sources to identify users of no-contract phones or burner phones.
This would also allow them to connect individuals with each other if someone let another person use their phone or they used a landline phone at someone else’s house. It would be, at this point, naive to think that the NSA is throwing out any information. While they may keep it out of whatever data system the FISA Court knows about – and really I believe they were never told of the existence of things like Marina or Mainway – this kind of information has to be kept somewhere else.
They are storing too large of a volume of information to not be capturing high volume phone number connections. You would think that if they weren’t doing that they would have the phone providers like ATT and Verizon strip or filter such numbers from the data they send under the court orders but rather we are left with the impression, or rather the FISC was, that there are data analysts and tech people that run clean ups against hundreds of millions of records each and every day against the same small pool of numbers. It would be cheaper to filter such stuff on the telecom side before sending it across the wire to NSA than it would to send all of it across the wire before filtering. The slowest part of the process is the speed of transfer across the wire.
I wouldn’t believe anything the government alleges about its systems or informs the FISA court about in any application or filing. For all we know the system names, database names, etc. that the NSA used in its filings (they are all redacted) aren’t even the names of systems as we know them from the various Snowden documents and the FISC truly has no idea just what it is they are approving. Not that it matters since they are willing to approve anything.
@Mindrayge: Doesn’t that ignore more banal HVNs, like telemarketers and pizza joints?
FWIW, I think the Data Integrity people also strip congressional and probably court numbers. So there’s more stripping, and it’s a damn site more intrusive, than they’re letting on.
@emptywheel: Not necessarily. Remember that one of the other purposes of collection activities has to do with international narcotics. Cash businesses such as pizza places and bars and restaurants are great for money laundering. They are also used to place orders for drugs – coded by ordering something not on the menu for example – there was a pizza place that was busted in the small town I live in (about 5,000 people) that had moved more than $1 million in drugs through it.
Foreigners also own these kinds of businesses and if they were connected with a terrorist or group they could easily hide the communications in the business calls if they knew the NSA wasn’t looking at them. Convenience stores and money orders, wire transfers, etc. Plus, a smaller establishment (non franchise) might be the best kind of place to do message drops between people that never converse directly. Leave a voice mail on a specific extension, for example.
Telemarketers may be something that could be avoided, except that many of these call centers are now in foreign nations. There is no way of knowing whether an outbound call from one of those call centers to a specific number in the US isn’t a direct call to discuss something other than a water filter system. It would provide the perfect cover if the NSA wasn’t looking at it.
I can’t see why they would leave either of those things out. They would be looking for calls in the telemarketing example, that went outside of an area code or range of exchanges for a geographic area. For a pizza shop they might look for an outbound call to some number after a particular number called in. They might look at cell phone calls to the pizza shop that is take out only but never find a cell phone location record of that person’s phone at the pizza shop. There are many other examples I can conceive of.
But if you consider any business, especially the largest, that make and receive many calls each day there is really no way to know who the employee is on the other end. There may or may not be a connection there. Either way it is something that can connect a location to a person just like they could with what ATMs a person uses or the stores they shop (via debit/credit) and that kind of connection is valuable to them. It allows them to connect that person with all others that are known to frequent that business whether or not they have ever communicated with each other in their lives.
I think that whatever filtering is going on is from the analyst access side of things. The data is all there only it just won’t be returned in their query. I am certain that there is at least one group that could access any and all of it. The analysts don’t like the “noise” as it slows them down – we saw that complaint in the MUSCULAR discussion concerning the capture of YAHOO e-mail boxes in the NArchive format (proprietary, in which the archive is the entire contents of a persons e-mail including contacts, folders, attachments, etc).
But, for the people running the show at NSA, it is all about building the biggest haystacks possible. Most of the people at NSA wouldn’t have the slightest clue about all of these systems and the kinds of massive collections behind their query screens. All they know is that they have to deal with weeding out noise and do checks for US persona and do minimization, etc. Many of these analysts work on quotas. They have to produce so many reports per shift, or week, or month – or they are out. There was at least one job ad out there that stated the job was in a quota-based production line environment. So one could easily imagine the kind of garbage that is all throughout the analysis artifacts, reports, etc.
The Toronto Globe and Mail article (and accompanying documents) concerning the Canadians diggin into the Brazilian Ministry of Mines and Energy. In the accompanying documents you can see that they were able to construct a retrieval flow from existing data sources (DISHFIRE, FASCIA, MAINWAY, and FASTBAT). The whole point of the system is to go into the haystack and see what is in it about any particular entity – in this case the Ministry of Mines and Energy. But it could be any entity not just a government agency but it could be any business at all. This is data mining ad-hoc and ala-carte.
Incidently, that document (slides) is a great wealth of information about what some of the code named systems have as content such as the metadata or event information they offer. Several systems where we had only ever seen then name before. In the example I cited above we have them going to MAINWAY for call metadata, FASCIA for cell location information and even PSTN (regular phone lines) info and events, DISHFIRE, for e-mail contacts and political connections (recall the documents about surveiling the Mexican Presidential candidate) and who knows what FASTBAT does.
Thanks to that document we know TOYGRIPPE is for VPN related collection as is FRIARTUCK. We know that the Target Knowledge system is called STARSEARCH and Targeting Requests are stored in a system called PEPPERBOX. EVILOLIVE, in addition to what the Wall Street Journal reported (if we can rely on it) about its internet content collection also holds GeoLocation records. VSAT phones and terminals are collected in a system called MASTERSHAKE. GSM Cell phone information is in a system called OCTSKYWARD.
When you see all these different systems collecting or storing or holding the results of processed raw SIGINT that obviously overlap in some ways it is obvious they are building the largest haystacks possible.
I’ve assumed for many years (since at least 2005, in point of fact), that EVERY digital transaction on any system not air-gapped – and given remote sensing technology, probably those too – is being sniffed, at minimum, and very likely recorded and stored. I just take it for granted that library cards, ATM cards, supermarket rewards cards, and the more obvious cellphone calls, text messages, VoIP, emails and all other electronic data is being vacuumed up for possible later retrieval.
In 2005, I couldn’t openly voice such convictions for fear of being subjected to ridicule and derision. My, how times have changed! And, for anyone who thinks the surveillance state was born out of 9/11, I suggest you Google “Echelon,” if you have the stomach for it, that is.
The entire discussion about “what can actually be gleaned from metadata” to me is equivalent to the old saw from Catholic elementary school religion classes, “How many angels can dance on the head of a pin?” Answer? Who gives a rip! If you use any kind of anything dependent on micro-circuitry and electronically stored data, somebody somewhere has you by the short hairs and, trust me, that’s where these revelations are ultimately headed. Make no mistake.