The August 20, 2008 Correlations Opinion
 On August 18, 2008, the government described to the FISA Court how it used a particular tool to establish correlations between identifiers. (see page 12)
On August 18, 2008, the government described to the FISA Court how it used a particular tool to establish correlations between identifiers. (see page 12)
A description of how [name of correlations tool] is used to correlate [description of scope of metadata included] was included in the government’s 18 August 2008 filing to the FISA Court,
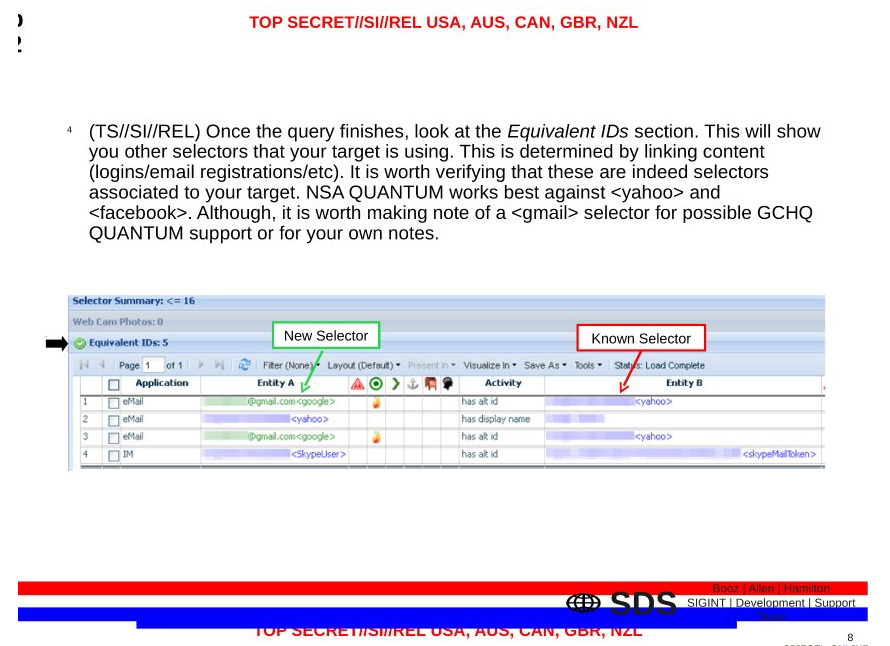
On August 20, 2008, the FISC issued a supplemental opinion approving the use of “a specific intelligence method in the conduct of queries (term “searches”) of telephony metadata or call detail records obtained pursuant to the FISC’s orders under the BR FISA program.” The government claims that it cannot release any part of that August 20, 2008 opinion, which given the timing (which closely tracks with the timing of other submissions and approvals before the FISC) and the reference to both telephony metadata and call detail records almost certainly approves the use of the dragnet — and probably not just the phone dragnet — to establish correlations between a target’s multiple communications identifiers.
As ODNI’s Jennifer Hudson described in a declaration in the EFF suit, the government maintains that it cannot release this opinion, in spite of (or likely because of) ample description of the correlations function elsewhere in declassified documents.
The opinion is only six pages in length and the specific intelligence method is discussed at great length in every paragraph of this opinion, including the title. Upon review of this opinion, I have determined that there is no meaningful, segregable, non-exempt information that can be released to the plaintiff as the entire opinion focuses on this intelligence method. Even if the name of the intelligence method was redacted, the method itself could be deduced, given other information that the DNI has declassified pursuant to the President’s transparency initiative and the sophistication of our Nation’s adversaries [Ed: did she just call me an “adversary”?!?] and foreign intelligence services.
[snip]
The intelligence method is used to conduct queries of the bulk metadata, and if NSA were no longer able to use this method because it had been compromised, NSA’s ability to analyze bulk metadata would itself be compromised. A lost or reduced ability to detect communications chains that link to identifiers associated with known and suspected terrorist operatives, which can lead to the identification of previously unknown persons of interest in support of anti-terrorism efforts both within the United States and abroad, would greatly impact the effectiveness of this program as there is no way to know in advance which numbers will be responsive to the authorized queries.
ACLU’s snazzy new searchable database shows that this correlations function was discussed in at least three of the officially released documents thus far: in the June 25, 2009 End-to-End Review, in a June 29, 2009 Notice to the House Intelligence Committee, and in the August 19, 2009 filing submitting the End-to-End Review to the FISC.
In addition to making it clear this practice was explained to the FISC just before the Supplemental Opinion in question, these documents also describe a bit about the practice.
They define what a correlated address is (and note, this passage, as well as other passages, do not limit correlations to telephone metadata — indeed, the use of “address” suggests correlations include Internet identifiers).
The analysis of SIGINT relies on many techniques to more fully understand the data. One technique commonly used is correlated selectors. A communications address, or selector, is considered correlated with other communications addresses when each additional address is shown to identify the same communicant as the original address.
They describe how the NSA establishes correlations via many means, but primarily through one particular database.
NSA obtained [redacted] correlations from a variety of sources to include Intelligence Community reporting, but the tool that the analysts authorized to query the BR FISA metadata primarily used to make correlations is called [redacted].
[redacted] — a database that holds correlations [redacted] between identifiers of interest, to include results from [redacted] was the primary means by which [redacted] correlated identifiers were used to query the BR FISA metadata.
They make clear that NSA treated all correlated identifiers as RAS approved so long as one identifier from that user was RAS approved.
In other words, if there: was a successful RAS determination made on any one of the selectors in the correlation, all were considered .AS-a. ,)roved for purposes of the query because they were all associated with the same [redacted] account
And they reveal that until February 6, 2009, this tool provided “automated correlation results to BR FISA-authorized analysts.” While the practice was shut down in February 2009, the filings make clear NSA intended to get the automated correlation functions working again, and Hudson’s declaration protecting an ongoing intelligence method (assuming the August 20, 2008 opinion does treat correlations) suggests they have subsequently done so.
When this language about correlations first got released, it seemed it extended only so far as the practice — also used in AT&T’s Hemisphere program — of matching call circles and patterns across phones to identify new “burner” phones adopted by the same user. That is, it seemed to be limited to a known law enforcement approach to deal with the ability to switch phones quickly.
But both discussions of the things included among dragnet identifiers — including calling card numbers, handset and SIM card IDs — as well as slides released in stories on NSA and GCHQ’s hacking operations (see above) make it clear NSA maps correlations very broadly, including multiple online platforms and cookies. Remember, too, that NSA analysts access contact chaining for both phone and Internet metadata from the same interface, suggesting they may be able to contact chain across content type. Indeed, NSA presentations describe how the advent of smart phones completely breaks down the distinction between phone and Internet metadata.
In addition to mapping contact chains and identifying traffic patterns NSA can hack, this correlations process almost certainly serves as the glue in the dossiers of people NSA creates of individual targets (this likely only happens via contact-chaining after query records are dumped into the corporate store).
Now it’s unclear how much of this Internet correlation the phone dragnet immediately taps into. And my assertion that the August 20, 2008 opinion approved the use of correlations is based solely on … temporal correlation. Yet it seems that ODNI’s unwillingness to release this opinion serves to hide a scope not revealed in the discussions of correlations already released.
Which is sort or ridiculous, because far more detail on correlations have been released elsewhere.

Note, if she did call you an “adversary”, it is an adversary of “our Nation”; so, so typically conflating herself and her organization and her country. If you’re not with them, you’re against them.
I don’t understand this statement of hers:
“The intelligence method is used to conduct queries of the bulk metadata, and if NSA were no longer able to use this method because it had been compromised, NSA’s ability to analyze bulk metadata would itself be compromised.”
Specifically, I don’t understand just why it is that the NSA would no longer be able to use this method if it were “compromised” (which I take to mean “made known to the public”). After all, “Connect all the dots” has been known for ages to be their mantra; what’s so new about the concept of connecting information from the emails and the internet and the phones?
If I’m right, then isn’t this argument against making it public a Bunch Of Crap?
quote”If I’m right, then isn’t this argument against making it public a Bunch Of Crap?”unquote
The standard “classified” label is BOC. In fact, every time an IC official opens his/her mouth you can consider it a BOC. However, this euphemism has been updated to..Bunch of Shit. That’s why you can smell the stench.
I think so–and had the same reaction. I’m not sure how someone works against this, except by using Tails constantly. Though I guess that works.
And, in the meantime, the European Court of Justice, the EU’s highest court, has voided a directive that ISPs and others retain all the sorts of information (like the dragnet info EW’s main post refers to), as being violative of the fundamental rights of the people and subjecting them to the feeling that they are under constant surveillance.
The press release: http://curia.europa.eu/jcms/upload/docs/application/pdf/2014-04/cp140054en.pdf
The judgment: http://curia.europa.eu/juris/document/document.jsf;jsessionid=9ea7d2dc30db4044b734702f47b68139a418a7d815ca.e34KaxiLc3qMb40Rch0SaxuNaN50?text=&docid=150642&pageIndex=0&doclang=EN&mode=req&dir=&occ=first&part=1&cid=378168
Keep in mind that queries against BR metadata can only return a contact chain. That was the order of the FISC. So BR metadata is likely already chained before analysts actually query it with a selector. Chaining on the fly doesn’t make sense to do especially if they are going to do correlation aggregating multiple contact chains together at some point.
There are more than one set of contact chain databases/systems out there. For example, JEMA contains MAINWAY chains and ASSOCIATION contains SMS contact chains from DISHFIRE. Both of those chain databases/systems are used to produce a composite graph. See the O Globo Fantastico slides from 9/3/13 (EFF document list).
It is unclear if there is a separate chain database/system that ties people together based on their location data. That is, whether or not people have been at a location at the same time or at the same location at different times within a defined period of time. I suspect there is one. Perhaps, this is what is described or implicated in the document they are withholding. The government seems to be rather concerned about any implication that they are tracking the movements of people – everybody – in the country. That is something that many more people would find troubling compared to the monitoring of who we contact. The idea of being followed, of being stalked, of being watched is a much more powerful non-starter.
I suspect there is a chain database/system for nearly every kind of selector type they have. No doubt there is a master chain database/system that holds merged/aggregated chains.
I can’t believe it is the graph merging/aggregating method that is super secret. Graph processing algorithms are known. Matrix processing methods are known – for example adjacency matrices. Linear Programming against multiple dimensions i.e. Hyperspaces is also known. I know they didn’t actually try explaining these things to the FISC. It isn’t easy for most people to pick up to begin with so it is highly unlikely that a judge was walked through an algorithm in any significant way, particularly the actual mathematical methods.
Clearly there is enough information out there for algorithm expert folks to be able to reason out the methodologies the NSA is using to connect chains, merge chains, etc. This isn’t exactly rocket science but the NSA is under the impression that it is or that they want to create such a perception. But even if they can’t discern the exact methodology the NSA uses the algorithm folks could devise how to do such aggregate chaining given what we know they collect.
I would put money on it being location centric and following the movements of people.
I think your observation about it being something to do with “location centric and following the movements of people” is highly likely. The Co-Traveler document is very persuasive (http://cryptome.org/2013/12/nsa-cotraveler.pdf)
.
I also think it has to do with “pattern recognition/pattern analysis” of those locations/movements. I don’t know the level of subtlety that’s involved with the NSA’s pattern analysis, but I suspect that with its bleeding edge high-powered computing facilities and highly-credentialed workforce, the level of subtlety for their searches and queries is beyond most of our imagination.
.
The NSA’s extensive use of this pattern recognition/pattern analysis would suggest to me that many of the NSA’s results of this activity produce a large number of false positives which is another way of saying that many innocent people are likely tarred with suspicion and having their electronic entrails picked apart by government analysts without regard for things like the constitutional rights.
Indeed, many false positives. I expect this goes beyond just cell phone location info. From bank transactions they can know what stores and what ATMs and gas stations we have been at and when and who else was there. Not with 100 percent certainty of course because someone could be using another person’s card. Same goes for credit cards. The most important thing about debit and credit cards isn’t what you bought but where you were and who was around in the area at the time or within a certain time period. This also goes for government assistance cards like SNAP.
.
They can do the same with reloadable public transit cards as well. Or EZ Pass and the like. Even OnStar and similar services will give up location information even if you are not a subscriber so long as it is equipped in the vehicle.
.
Even the use of a land line telephone gives up location information. Airline and hotel reservations, obviously.
.
Definitely Co-Traveler is the kind of thing they are after. The Canadian exercise that was documented in their airports was yet another. No doubt they are attempting to do this with all the location information they can get from as many different sources as possible.
.
It is pretty hard today to avoid giving up your location in some manner several times a day and even if you were attempting to avoid giving up location info as much as possible you likely would get tripped up by something along the way.
.
Naturally I expect they are correlating other things like the items you do purchase at stores – they have to get that from the stores themselves as the credit/debit purchase doesn’t tell what you bought only the time, place, and location of a purchase. “Reward card” usage would be an example. They could get that from the clearinghouses that process those.
.
Gun registrations and purchases, for sure. Ammunition purchases and the like. That would raise hackles but would seem to me to be not much more than the hackles raised with firearm regulations already.
.
I hope that among the documents Edward Snowden passed on to journalists is one showing the extent of this correlation activity.