Matt Taibbi Is Furious that Election Integrity Project Documented How Big Trump’s Big Lie Was
As you’ve no doubt heard, #MattyDickPics Taibbi went on Mehdi Hasan’s show yesterday and got called out for his false claims.
“Well, that, then, is an error.”
– @mtaibbi, confronted with previously unacknowledged mistakes in his Twitter Files reporting, by @mehdirhasan.Watch the full conversation later tonight: https://t.co/WI2GDlekQP pic.twitter.com/iYM1n7xOaN
— The Mehdi Hasan Show (@MehdiHasanShow) April 6, 2023
After the exchange, #MattyDickPics made a show of “correcting” some of his false claims, which in fact consisted of repeating the false claims while taking out the proof, previously included in the same tweet, that he had misquoted a screen cap to sustain his previous false claim.
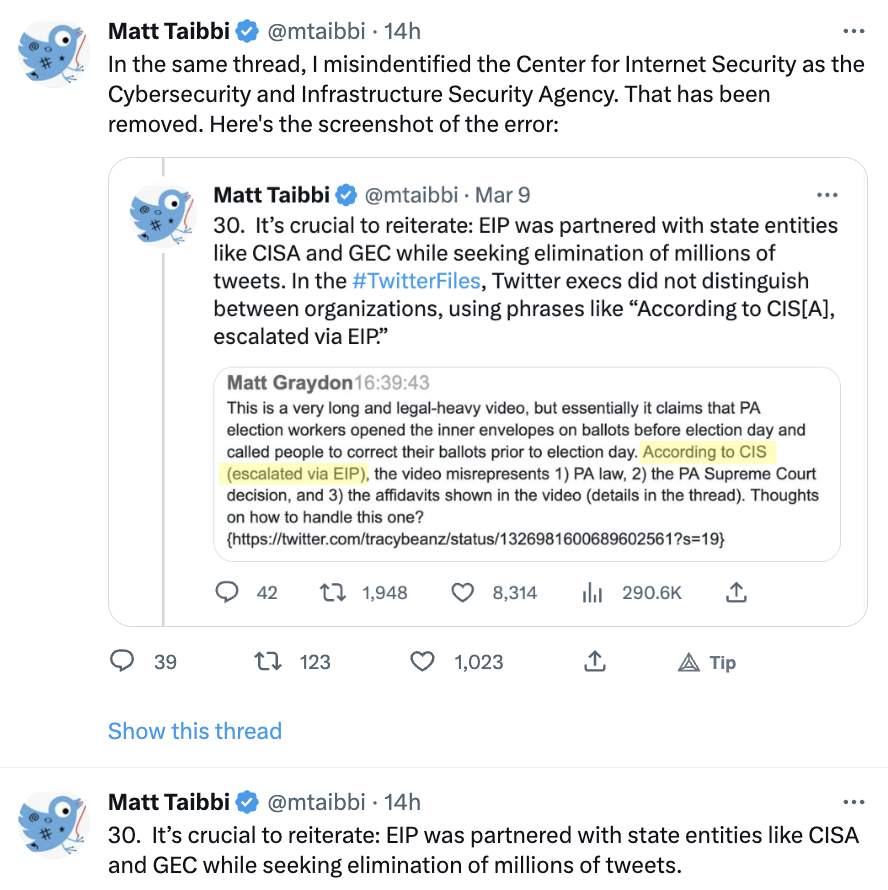
#MattyDickPics made a mishmash of these same claims in his sworn testimony before Jim Jordan’s committee, which may be why he doesn’t want to make wholesale corrections. I look forward to him correcting the record on false claims made under oath.
#MattyDickPics also wrote a petulant post announcing that MSNBC sucks, in which, after a bunch of garbage that repeatedly cites Jeff Gerth as a factual source (!!!), finally gets around to admitting how sad he is that no one liked his Twitter Files thread making claims about the FBI.
After the first thread, Mehdi was one of 27 media figures to complain in virtually identical language: “Imagine volunteering to do PR work for the world’s richest man.”
I laughed about that, but couldn’t believe the reaction after Twitter Files #6, showing how Twitter communicated with the FBI and DHS through a “partner support channel,” and in response to state requests actioned accounts on both sides of the political aisle for harmless jokes. Mehdi’s take wasn’t that this information was wrong, or not newsworthy, but that it shouldn’t have been published because Elon Musk put Keith Olbermann in timeout for a day, or something. “Even Bari Weiss called him out, but Taibbi seems to want to tweet through it,” Mehdi tweeted.
If it sounds like my beef with MSNBC is personal, by now it is. Take the Twitter Files. When first presented with the opportunity to do that story, my first reaction was to be extremely excited, as any reporter would be, including anyone at MSNBC. In the next second however I was terrified, because I care about my job, and knew there would be a million eyes on this thing and a long way down if I got anything wrong. If you’ve ever wondered why I look 100 years old at 53 it’s because I embrace this part of the process. Audiences have a right to demand reporters lie awake nights in panic, and every good one I’ve ever met does.
But people who used to be my friends at MSNBC embraced a different model, leading to one of the biggest train wrecks in the history of our business. Now they have the stones to point at me with this “What happened to you?” routine. It’s rare that the following words are justified on every level, but really, MSNBC: Fuck you.
As I showed, #MattyDickPics made a number of egregiously false claims in that very same Twitter Files #6, the very same one he’s stewing over because it wasn’t embraced warmly.
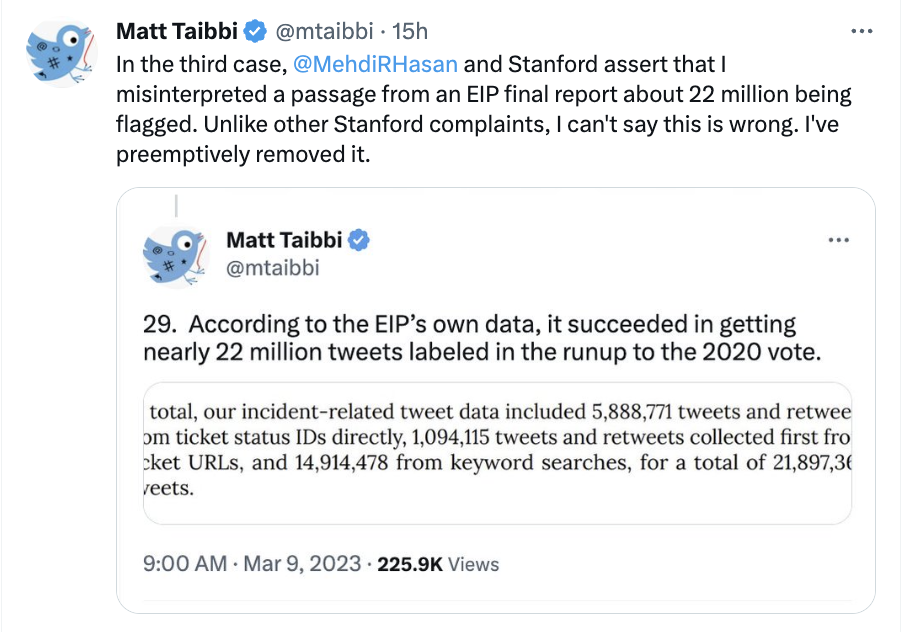
But one of the other key false claims Mehdi caught #MattyDickPics making is far more important: the claim that the Election Integrity Project “censored” 22 million tweets; in his tweet, he claimed that “According to EIP’s own data, it succeeded in getting nearly 22 million tweets labeled in the runup to the 2020 vote.”
After Mehdi posted the appearance, #MattyDickPics “removed” his error.
Then, after a guy named Mike Benz, who is at the center of this misinformation project, misinformed him, #MattyDickPics reverted to his original false claim.

As to the factual dispute, there is none. #MattyDickPics and his Elmo-whisperer Mike Benz are wrong. The error stems from either an inability to read an academic methodology statement or the ethic among these screencap boys that says you can make any claim you want so long as you have a screencap with a key word in it.
At issue is a report the Election Integrity Project released in 2021 describing their two-phase intervention in the 2020 election. The first phase consisted of ticketing mis- or disinformation in real time in an attempt to stave off confusion about the election. Here’s the example of real-time ticketing they include in their report.
To illustrate the scope of collaboration types discussed above, the following case study documents the value derived from the multistakeholder model that the EIP facilitated. On October 13, 2020, a civil society partner submitted a tip via their submission portal about well-intentioned but misleading information in a Facebook post. The post contained a screenshot (See Figure 1.4).
Figure 1.4: Image included in a tip from a civil society partner.
In their comments, the partner stated, “In some states, a mark is intended to denote a follow-up: this advice does not apply to every locality, and may confuse people. A local board of elections has responded, but the meme is being copy/pasted all over Facebook from various sources.” A Tier 1 analyst investigated the report, answering a set of standardized research questions, archiving the content, and appending their findings to the ticket. The analyst identified that the text content of the message had been copied and pasted verbatim by other users and on other platforms. The Tier 1 analyst routed the ticket to Tier 2, where the advanced analyst tagged the platform partners Facebook and Twitter, so that these teams were aware of the content and could independently evaluate the post against their policies. Recognizing the potential for this narrative to spread to multiple jurisdictions, the manager added in the CIS partner as well to provide visibility on this growing narrative and share the information on spread with their election official partners. The manager then routed the ticket to ongoing monitoring. A Tier 1 analyst tracked the ticket until all platform partners had responded, and then closed the ticket as resolved.
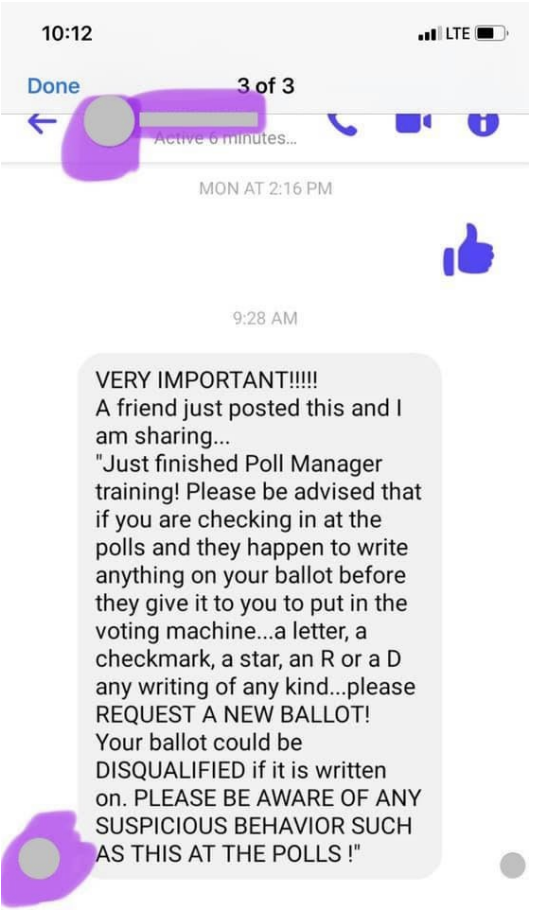
It wasn’t a matter of policing speech. It was a matter of trying to short circuit even well-meaning rumors before they start going viral.
According to the report, social media companies acted on 35% of the identified tickets, most often those claiming victory before the election had been called. Just 13% of all those items ticketed were removed.
35% of the URLs we shared with Facebook, Instagram, Twitter, TikTok, and YouTube were either labeled, removed, or soft blocked. Platforms were most likely to take action on content that involved premature claims of victory.
[snip]
We find, overall, that platforms took action on 35% of URLs that we reported to them. 21% of URLs were labeled, 13% were removed, and 1% were soft blocked. No action was taken on 65%. TikTok had the highest action rate: actioning (in their case, their only action was removing) 64% of URLs that the EIP reported to their team.
Then after the election, EIP looked back and pulled together all the election-related content to see what kinds of mis- and disinformation had been spread, including after the election. Starting in Chapter 3, the report describes the waves of mis- and disinformation they identified, starting with claims about mail-in voting, to claims about how the votes would be counted, to organized efforts to “Stop the Steal” that resulted in the January 6 attack. It looked at a number of case studies, including Stop the Steal, the false claims about Dominion that have already been granted a partial summary judgment in their Fox lawsuit, and nation-state campaigns including the Iranian one that involved posing as Proud Boys to threaten Democratic voters that #MattyDickPics has systematically ignored.
Chapter 5 describes the historic review that #MattyDickPics misrepresented. It clearly describes that this analysis was done after the fact, starting only after November 30.
Through our live ticketing process, analysts identified social media posts and other web-based content related to each ticket, capturing original URLs (as well as screenshots and URLs to archived content). In total, the EIP processed 639 unique tickets and recorded 4,784 unique original URLs. After our real-time analysis phase ended on November 30, 2020, we grouped tickets into incidents and narratives. We define an incident as an information cascade related to a specific information event. Often, one incident is equivalent to one ticket, but in some cases a small number of tickets mapped to the same information cascade, and we collapsed them. As described in Chapter 3, incidents were then mapped to narratives—the stories that develop around these incidents—where some narratives might include several different incidents. [my emphasis]
Then it describes how it collected a bunch of data for this historic review. One of three sources of data used in this historic review was Twitter’s API (the other two were original tickets and data from Facebook and Instagram). Starting from a dataset of 859 million tweets pertaining to the election, EIP pulled out nearly 22 million tweets that involved “election incidents” of previously identified mis- or disinformation.
We collected data from Twitter in real time from August 15 through December 12, 2020.1 Using the Twitter Streaming API, we tracked a variety of election-related terms (e.g., vote, voting, voter, election, election2020, ballots), terms related to voter fraud claims (e.g., fraud, voterfraud), location terms for battleground states and potentially newsworthy areas (e.g., Detroit, Maricopa), and emergent hashtags (e.g., #stopthesteal, #sharpiegate). The collection resulted in 859 million total tweets.
From this database, we created a subset of tweets associated with each incident, using three methods: (1) tweets recorded in our ticketing process, (2) URLs recorded in our ticketing process, and (3) search strings.
Relying upon our Tier 1 Analysis process (described in Chapter 1), we began with tweets that were directly referenced in a ticket associated with an incident. We also identified (from within our Twitter collection) and included any retweets, quote tweets, and replies to these tweets. Next, we identified tweets in our collection that contained a URL that had been recorded during Tier 1 Analysis as associated with a ticket related to this incident. Finally, we used the search string and time window developed for each incident to identify tweets from within our larger collection that were associated with each election integrity incident.
In total, our incident-related tweet data included 5,888,771 tweets and retweets from ticket status IDs directly, 1,094,115 tweets and retweets collected first from ticket URLs, and 14,914,478 from keyword searches, for a total of 21,897,364 tweets.
Here’s the EIP table of its top-10 most viral examples of mis- or disinformation, amounting to over 14 million of the tweets in question. Right away, it should alert you to the effect, if not the goal, of conflating EIP’s real-time tickets to social media companies, including of things like an overgeneral statement about how ballots are treated in different states, with what EIP found in their historical review of how mis- and disinformation worked in 2020.
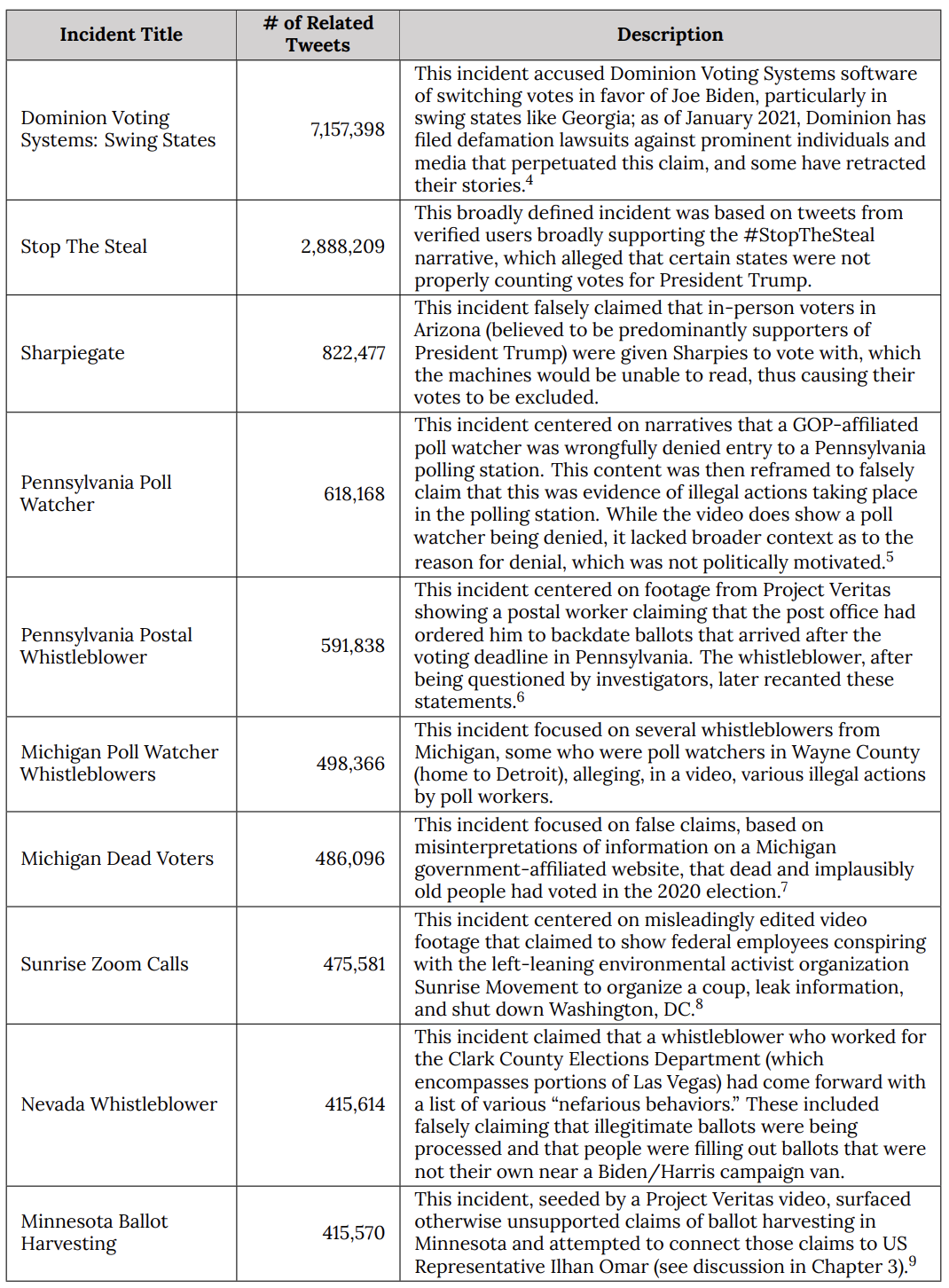
What #MattyDickPics and his Elmo whisperer Mike Benz are complaining about is not that EIP attempted to “censor” speech in real time. What they’re complaining about is that a bunch of academics and other experts figured out what the scale and scope of mis- and disinformation was in 2020. And what those experts showed is that systematic Republican disinformation (and mind you, this is just the disinformation through December 12; it missed the bulk of the build-up to January 6) made up the vast majority of mis- and disinformation that went viral in 2020. It showed that, even by December 12, almost 45% of the mis- and disinformation on Twitter consisted of two campaigns tied to Trump’s Big Lie, the attacks on Dominion and the organized Stop the Steal campaign.
EIP’s list of repeat spreaders is still more instructive, particularly when you compare it against the list of people that Elmo has welcomed back to Twitter since he took over.
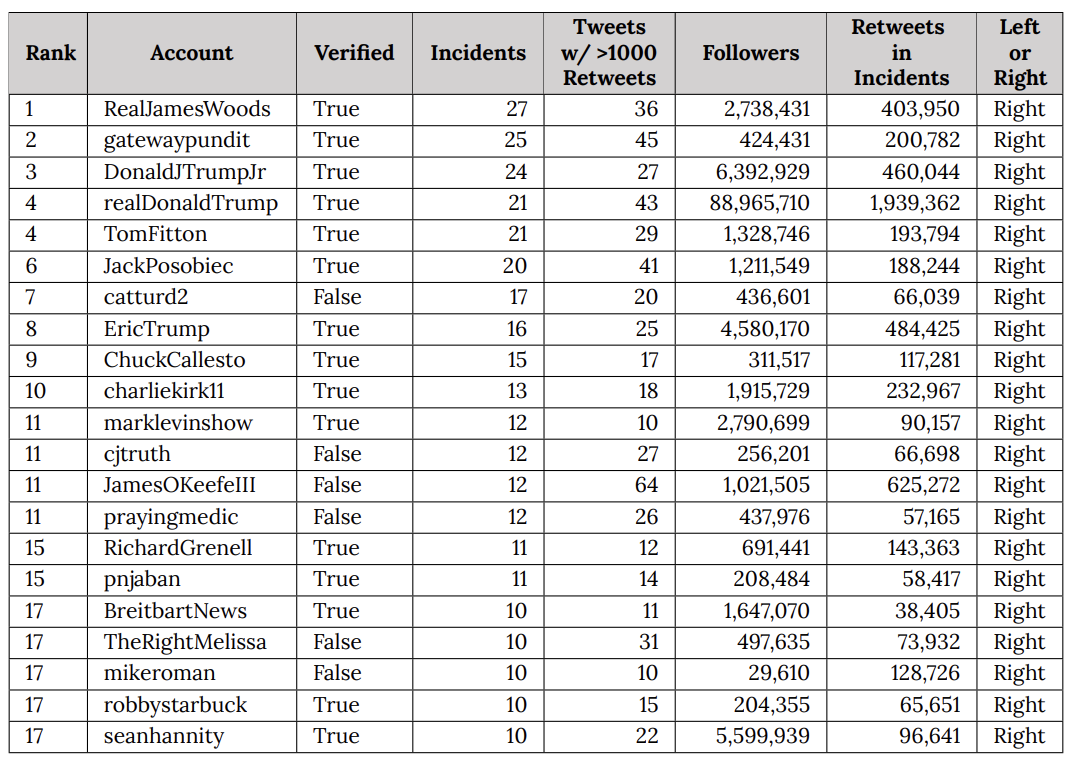
What EIP did was catalog how central disinformation from Trump and his family — and that of close allies in the insurrection — was in the entire universe of mis- and disinformation (Mike Roman, one of least known people on this list, had his phone seized as part of the January 6 investigation last year).
Some mis- and disinformation did not go viral in 2020. What did, overwhelmingly, was that which Trump and his allies made sure to promote.
The dataset of 22 million tweets is not a measure of mis- or disinformation identified in real time. What it is, though, is a measure of how central Trump is to disinformation on social media.
Whether #MattyDickPics understands the effect of the stubborn false claim that Mike Benz fed him, whether #MattyDickPics understands how his false claim provides Elmo cover to replatform outright white supremacists, or not, the effect is clear.
The concerted effort to discredit the Election Integrity Project has little effect on flagging mis- or disinformation in real time. What it does, however, is discredit efforts to track just how central Trump is to election disinformation in the US.
Update: Here’s the full Mehdi Hasan interview.
Update! Oh no!! Drama!!



Marty and his buddy Bari illustrate the importance of working for a reliable entity with editors that will help you see the bigger picture and lawyers that protect you from your worst egotistical impulses. Independent blog spots, like this one, are important but it would not be a good idea to do away with institutional journalism completely.
That would be MATTY, damn autocorrect!
Yeah, that fanged thing spews up have my text massages. I shout it off
Phenomenal detail in this powerful analysis! Deserves much broader circulation. THANKS!
Can you verify the claims made here and here? https://cyber.fsi.stanford.edu/io/news/background-sios-projects-social-media https://www.cip.uw.edu/2023/03/16/uw-cip-election-integrity-partnership-research-claims/
I quote:
“No, the EIP did not censor any tweets or label any tweets as “misinformation.” EIP has no ability to remove or label tweets or other posts, and content moderation decisions are independently made by social media platforms. As part of its non-partisan research relating to the 2020 U.S. presidential election, EIP analyzed 22 million tweets that contained keywords or URLs relevant to EIP’s scope of work. EIP identified 2,890 unique tweet URLs in potential violation of Twitter’s stated policies. EIP provided its factual analysis to the relevant platforms, which were then responsible for each platform’s own content moderation decisions. The EIP informed Twitter and other social media platforms when certain social media posts violated each platform’s own policies; EIP did not make recommendations to the platforms about what actions they should take.”
I’ve heard people claim that the individual “tickets” that the EIP sent were multiple tweets. For example: https://stacks.stanford.edu/file/druid:tr171zs0069/EIP-Final-Report.pdf#page=47 It looks like this “ticket” was actually multiple tweets.
Mike Benz says https://twitter.com/MikeBenzCyber/status/1644111356709289993 :
“The 3000 URLs he is anchoring you to were sent as samples for censorship guidance to squash millions of related posts.”
Did Twitter squash millions of related posts? As far as I can tell, the 22 million number includes retweets. So if the EIP flagged a singular tweet, and Twitter took action on that tweet, and that tweet had 5000 retweets, that would count as Twitter taking action on “5000 tweets” (but there was only one original tweet that was being spread). Is that correct?
[Welcome to emptywheel. Please choose and use a unique username with a minimum of 8 letters. We are moving to a new minimum standard to support community security. Because your username is far too common it will be temporarily changed to match the date/time of your first know comment until you have a new compliant username. Thanks. /~Rayne]
You’re confusing exactly the points Marcy clarified in the post.
The 22 million number is the total number of tweets they studied when looking for mis- and dis-information AFTER THE ELECTION. It has nothing to do with their real time monitoring and has absolutely nothing to do with Twitter’s moderation decision.
I think the larger point and the (almost certainly bullshit) pivot Matt is making is that the “incidents” could consist of thousands of tweets. So I guess the question is: what was the total impact of the real-time effort in terms of the number of tweets that were removed? I’m having trouble finding a concise summary of this in the report.
I don’t think it matters one way or another for his credibility, which is shot, but I am curious. I mean, I hope they were highly effective and removed as many as possible. It’s insane to me that someone would look at the nature of what this group was reporting and think: “no actually we want more people being mislead about when to vote or what’s a valid vote”.
[Welcome to emptywheel. Please choose and use a unique username with a minimum of 8 letters. We are moving to a new minimum standard to support community security. Because your username is far too common it will be temporarily changed to match the date/time of your first know comment until you have a new compliant username. Thanks. /~Rayne]
The 22 million tweets were something like 3% of the 859 million elected-related tweets.
“Now they have the stones to point at me with this “What happened to you?” routine.”
I often wonder what happened to him too.
Yep, me too…
Me three. In a way the most distressing thing is the sense of creeping doubt. Suddenly you have to ask yourself: was all the stuff he wrote before that sounded good to me just as rickety and wrong as this stuff? When the rot at the MSM really shifted into gear, I found myself relying more and more on other sources. Over time I’ve given up on many of them (Greenwald, Hedges, Hersch, for example). This site isn’t the only one I look at, but it’s the only one I’ve found that I feel I can trust absolutely. [note to self — time to make another contribution!]
Yeah, I have given up on the same writers. Taibbi to start, but Greenwald, Hedges, and…very sadly… Hersch. Vonnegut still holds up though. So it goes.
[Welcome to emptywheel. SECOND REQUEST: Please choose and use a unique username with a minimum of 8 letters. We are moving to a new minimum standard to support community security. Thanks. /~Rayne]
Yes as to all that.
Their work reporting on the financial crisis was quite good, but something infected their brains during that period apparently. I can’t speak for any of their writing before around 2007, but they rightly suspected that there was a good deal of rot and corruption underneath the financial edifice that enabled the housing bubble. The problem is they then took that suspicion and ran with it, as if somehow the corruption in the financial system that was exposed meant that every institution was suspect. From there, it was just down the rabbit hole of deep state, conspiracy type thinking. Once they had turned on the government as part of the problem, and Trump as the solution, and latched onto that steaming pile of dung, there was no place good they could end up.
“Once they had turned on the government as part of the problem, and Trump as the solution,”.
Matti’s Conversion, (or inexorable slide) to being a PR hack for a billionaire rather than an actual journalist is clear if he considers Trump a ‘solution’ to anything. Except perhaps if you are a ceo looking to reduce corporate and other personal taxes……..estate, income, private jet, etc.
Thank you for this helpful and detailed clarification.
Taibbi and Benz seem to make and then repeat two analytical errors. 1) Counting misinformation post election is the same as “censoring” it pre-election. 2) If a private agent (EIP) has ever spoken to law enforcement, it is “censorship” if the private agent reports to other private agents (Twitter, FB) content that might violate their terms of service.
Yes. What has happened with the Twitter Files is they looked and didn’t find what they expected (and what Lee Fang falsely had told them they would find). So they moved onto the NGOs that do disinformation research, and based on (often misrepresenting) their funding, they’re claiming that’s censorship instead.
Ultimately, though, the entire effort seems to be an effort to make Twitter safe for fascism.
I was previously dubious about the notion that Elon Musk bought Twitter to sincerely advance a kind of right/fascist agenda. I felt that $44 billion was enough of a barrier, or maybe he was making moves he thought worked on paper, or in his Wile-E super-genius mind. I can also theoretically understand the potential mind bending power of controlling some part of the world’s discourse, along with the ego eruption of having millions of new addicted fanboys. I also under how the perception of being on the winning side of a Musk jihad can intoxicate a Taibbi or others to try and bring the goods. But its not feeling like that to me anymore, because every move he’s making seems to be designed to make Twitter a 100% disinformation site, and it feels more like tagging NPR as a state media entity, or helping the NY Times not buy expensive blue checkmarks is part of a plan to get all standard media off Twitter. All this with the knowledge that Musk himself values Twitter at $22 billion and the finance world that is close to valuing it at $0. Now I wonder if this is on the agenda of the next SPECTRE meeting or something.
On the money.
Well said.
There seem to be two gaps in the “censorship by NGO” story. One gap is that the argument that the NGO is a state actor because of some tenuous or misrepresented (as you say) connection is hooey. The other gap is that the NGO, at least in this instance, seems only to have reported posts as possbily violating the TOS, leaving the decision about what to do about them to the platforms. The platforms seemed to have only taken action a few times. So we have two rungs missing in the ladder, or two links missing in the chain, or whatever is the right metaphor, to establish “censorship.”
Great piece of detailed work – I suppose #matty.. will never really recover from this- the look on his face when the picture of him and Ted(incurableskincondition)Cruz came up was priceless- his vocal chords just dried up during the interview as he sank deeper and deeper – I hope he tries to respond to your article – keep up the good work
Mattydickpicks seems to have as much trouble reading as he does with women. He is unable to deal with the inherent conflicts involved in synthesizing new information, which inevitably won’t all fit into preexisting pigeon holes. Like his audience, he is only comfortable inside his bubble – so long as it is as lucrative as his dreams. I imagine there are hundreds of women in Moscow still laughing at his dilemma and relieved that he is anywhere except Moscow.
I guess Substack pays better and more reliably than the richest man in the world. Who knew?
Hold that thought. Did you know Substack had to raise cash last week?
Cracks me up that Taibbi has been a useful idiot applied to satisfy Elmo’s ex-wife, who asked Elmo to buy Twitter: “Please do do something to fight woke-ism. I will do anything to help!” “Can you buy Twitter and then delete it, please!? xx”
Oh yes, kiss-kiss, and none for Taibbi. Imagine torching what was left of your professional reputation to end up holding Talulah Riley’s handbag containing Elmo’s nuts.
Should have mentioned in my above comment: along with the brilliant sleuthing and thinking and writing, we get coffee-out-the-nose-brilliant comic relief.
This reminds me of a different issue: among the change that Elmo is pushing in twitter is closing free API access to Twitter data. They plan to change 200k/month or more to get access to this data, a move that would price out all academic research that use twitter-based data. At first, I thought it is just another ill-conceived scheme to make more profit, and that he just doesn’t care about the impact. But now I’m starting to think this may be intentional. Elmo and his friends just don’t want academic research that analyze disinformation on twitter.
There has been great academic tracking of misinformation through Twitter and across other platforms, it totally makes sense that Musk would want to end that. https://www.cip.uw.edu/
He’s impossible to even talk to, total douche. He’s probably getting donations from anonymous people and pretending it’s legitimate
What a whiny weasel Matty is. I couldn’t watch beyond 10 minutes of his smirking evasion.
Would it be unkind to describe Taibbi’s ideology (along with Greenwald, Aaron Mate, Tracey, Dore et al.) as political incelism?
Not at all. Here’s more:
Ungrounded Deep Statists
Horseshoe Contrarians
Self-Appointed Narrative-Influencers
Profiteering Pundits
Whatever the phrase is that describes those who go where to the juice is while pretending to be factual.
It’s not hard to conclude they’d be far happier in Hell with a microphone than in Heaven listening.
I can’t hold my nose long enough to follow what’s going on with Twitter sandbagging Substack, but I think it’s hilarious that it seems to have flummoxed Taibbi.
I definitely don’t have the stomach to dig into Bari Weiss’s reaction, but I sure hope she’s hurting too.
She hitched her wagon to a loon’s crusade even as all of the people she looks down on were raising an alarm. She is such a pompous reactionary she just assumed if the people who don’t like her don’t like Musk, then Musk must be doing something right. And now her Substack is caught in the crossfire. Not that she’ll learn anything.
“Lucrative Substack you got there, Matt. It would be a shame if something terrible should happen to it. Think of all the followers Elon helped you acquire. Why aren’t you buying your ‘cheese’ from Elon’s mozza and protection shop?”
Elon Musk’s next purchase: Substack. He’s as vengeful as the Don. :-)
What I really, REALLY enjoy about Musk’s tantrum aimed at Substack is that Andreesen Horowitz a16z VC is among Twitter’s financiers — and a16z funded Substack.
I should elaborate on the techbros’ circular firing squad in my next post.
Only Musk rat could make me give a shit about Sub Stack.
Not sure you’re correct there. Eventually one of them will take off, and (if you’re Elmo) it’s best to kill them before they take off.
Lol, I am certain that, at least for me, and as of now, I am indeed correct. And, no, I am not going to kill an existing superior platform with the blind hope that, maybe, someday, a usable alternative may crystallize. Twitter still works quite fine for me and I don’t pay Musk anything. I do not owe the holier than thou people demanding I leave for Mastodon, or anywhere else, anything.
I still laugh, grimly, how the Twitter takeover only happened because some exec at Morgan Stanley thought it was a good idea to lock themselves into an unbreakable agreement to commit themselves to billions of debt just because Musk told them it was a good deal.
Anyone could have told Morgan Stanley the direction the Fed was going with interest rates made this a dumb risk. If he threatened them with going elsewhere if they insisted on pushing the risk back on him, they should have called his bluff.
Nope. They were sure they could dump the debt ASAP, they were sure Tesla’s stock would go up from $300, and they were sure Musk couldn’t have gotten any nuttier.
Great work building the Morgan Stanley brand!
It was pretty much the same everywhere with investment in Big Tech, though, including their financial ecosphere. That’s what brought us SVB’s collapse — too much lock-in in one pot, no systemic analysis.
No kidding, the level of systemic analysis for major deals pretty much consists of poor grunts scrambling to come up with numbers to back up what the fancy suits have already committed to.
Low level quants are being brow beaten all the time with the questions “are you sure you want to be the one to make this deal fall through? Can’t you look a little harder?”
It’s basically a replay of Cheney going to analysts in 2002.
And a replay of all the crap that led to the crash of 2008.
[rant]
THERE IS SO MUCH FVCKING CRAP GOING ON THAT IT’S IMPOSSIBLE TO EVEN JUST KEEP UP
[end rant]
You rant very efficiently, I must say. :-)
:-) That comes from LOTS of practice!
This is what broke this camel’s back this morning [retweeted by Marcy]:
Clarence Thomas’s Billionaire Benefactor Collects Hitler Artifacts
Harlan Crow also reportedly has a garden full of dictator statues. https://www.washingtonian.com/2023/04/07/clarence-thomass-billionaire-benefactor-collects-hitler-artifacts/ [] SYLVIE MCNAMARA APRIL 7, 2023 []
Yes, I noticed that. So Jim’s little brother, Harlan Crow (white-haired nepo-baby to his folks real estate fortune), made a good friend when he discovered a recently seated Supreme Court Justice shared his admiration of amateur German cityscape paintings. I’ll bet ol’ Harlan really thought of his new friend as one of the good ones…you know, a credit to his race.
And the fact that he was a SCOTUS Justice sympathetic to his own, ummm, mildly authoritarian leanings? Just a happy coincidence of course!
It’s impossible to say anything about Thomas (and his hideous harridan of a wife) that’s actually ugly enough to describe the couple’s sheer awfulness. I could cuss like a demon with Tourette’s syndrome and not come close to conveying it!
… “an ‘ARTICULATE’ credit to his race”.
” I look forward to him correcting the record on false claims made under oath.”
Oh THAT’S why he left Twitter and why Musk hid his posts! They’re limiting legal exposure!
Man, I’m getting old, for a while there I actually thought Taibbi might be capable of feeling shame.
The uniformity of thought on blog discussions is disturbing. Here the tone is “Yeah, that punk Taibbi got owned!”. The take over at NakedCapitalism is the opposite: “The evil Dems suppress Taibbi because he subverts their narrative!”
https://www.nakedcapitalism.com/2023/04/why-do-mainstream-democrats-hate-matt-taibbi.html
There’s nary a comment there that doesn’t speak of our intrepid reporter in glowing terms. I’m wondering how engineered all this is because my comment there was placed into moderation and never appeared. I’ll try posting here.
~~~~~
I’m not sure why Thomas Neuburger is confused about why lefties (not just Democrats) would have a change of heart about Taibbi. His previous work was critical of those in power, while his Twitter stuff can be seen as carrying water for one of America’s premier oligarchs.
The Twitter Files was simply a public relations stunt by Musk to promote his new toy. Taibbi seems delusional when he states this was his most important work. After being called out by Mehdi Hasan to his face for lazy reporting and only being able to muster feeble, mumbling responses, I can see why people wouldn’t trust the man.
~~~~~
That seems like a harmless take, no?
[Welcome to emptywheel. Please choose and use a unique username with a minimum of 8 letters. We are moving to a new minimum standard to support community security. Because your username is far too common it will be temporarily changed to match the date/time of your first know comment until you have a new compliant username. Thanks. /~Rayne]
Hi there are, welcome to Emptywheel. But you will have to modify your user name to comply with our eight character minimum rule. Please notify us when you have done so.
The “uniformity of thought of blog discussions” seems like a bad take to me. We don’t really have that here. I personally know Tom Neuberger, but waste exactly zero time at Yves’ Naked Capitalism. I never had a change of heart about Taibbi, I always thought he was an insufferable misogynistic asshole (although his squid term for the bankers was funny for a short while).
Most small blogs seem to have a cliquish feel… but I’ll read emptywheel a bit and reserve judgement for now.
I found you via Mastodon, so thanks for a supporting open social media. What I’d really like to see is a widely adopted, federated commenting layer used by blogging software so both readers and writers don’t have to be burdened by moderation.
Mastodon already is an informal commenting layer which goes unmoderated by blogs and only the instances’ moderation.
Because regulations like Section 230 can change at any time with the political winds, it’s better not to have a wholly unaffiliated layer attached to a blog.