21% of the Database Query Errors in NSA Report Involved the Phone Internet Dragnet Database
 Update: as Mindrayge notes, Marina appears in NSA slides as Internet, not phone metadata (and that’s how Ambinder refers to it here). There are some oddities, then, but I am changing this post accordingly.
Update: as Mindrayge notes, Marina appears in NSA slides as Internet, not phone metadata (and that’s how Ambinder refers to it here). There are some oddities, then, but I am changing this post accordingly.
As I noted in this post, the May 3, 2012 audit of NSA’s violations falsely suggests “roamer” problems were the cause of an increase in incidents, rather than database query errors, transit collection, and detask problems.
Database query errors are basically when an analyst collects too much data because she doesn’t exclude data that should be excluded, she ran a query believing it was appropriate because she had too little information on it, or she ignored standard operating procedures.
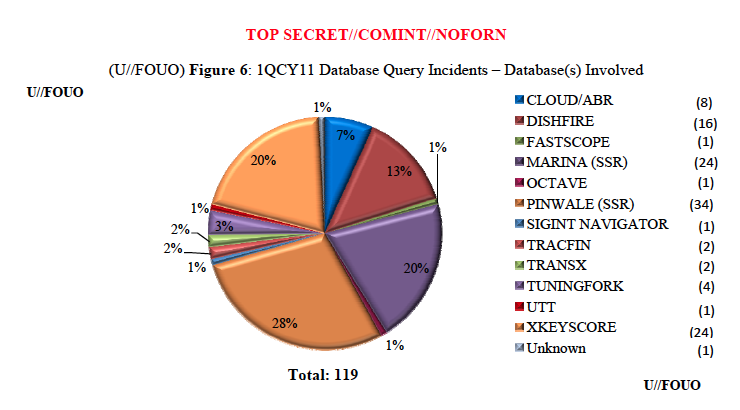
In addition to telling us how many database query problems there were, the report tells us which NSA databases they involved. As the figure above notes, 24 of those errors involved the MARINA database. There were actually 115 total query errors — 4 involved multiple databases — which means 21% of the database query errors involve MARINA.
As Marc Ambinder and others have reported, MARINA is the name of the Section 215 phone records dragnet database.
The telephone metadata is stored in a database called MARINA, which keeps these records for at least five years.
In other words, a fifth of the database query errors in the first quarter of 2012 were on the US phone Internet record dragnet database — the one the government has been claiming is so carefully guarded.
[If Mainway is just Internet metadata, then we don’t know the number of queries.]
Not only that, but we have a rough idea of how common query errors on this database are. The government has told us that queries were made on fewer than 300 identifiers in 2012. While it’s not a one-to-one comparison (some identifiers would have been run more than once), that means perhaps as many as 8% of the queries on the dragnet database involved some kind of error, including errors like not following procedures. And that’s assuming analysts didn’t keep making errors with the database at the same rate they did in the first quarter: if they kept up the same error pace, the error rate might be closer to 32%
But don’t worry, the government tells us, our phone record data are safe, even with a potential error rate of 32% accessing that data.
Update: LAT’s Ken Dilanian, who listened to a conference call NSA just had, just tweeted this:
NSA’s DeLong will not say how often NSA makes privacy errors when it queries US phone records database. But less than 30%, he says.
I asked is the rate between 8 and 30%, and he said 30% isn’t right. So, you may be on to something.
Less than 30%?!?!? That suggests it is probably far higher than even I imagined. Even if it was 8% it would be unacceptably high. But if it’s at the higher end of the possible range, it is unbelievably high.
Update: Ron Wyden and Mark Udall have issued a statement on this. Among other statements, they emphasize that Americans need to know about the phone and Internet dragnet violations.
Americans should know that this confirmation is just the tip of a larger iceberg.
[snip]
In particular, we believe the public deserves to know more about the violations of the secret court orders that have authorized the bulk collection of Americans’ phone and email records under the USA PATRIOT Act.
Given the potential numbers of phone dragnet violations, I should say so.
Update: Fixed “a fifth” for “a quarter.” Now I’m making NSA type simple math errors!
According to various interviews with Tom Drake and William Binney, Thinthread would have prevented these abuses; but, hey, we can’t deprive private enterprise of a pot full of money, even if those enterprises aren’t nearly as clever as they think they are.
Meanwhile, I have the distinct impression that the Post and the Guardian, perhaps at an earlier moment, have coordinated which paper is going to release which piece of information–and it’s all being carefully scheduled not to overlap. I was genuinely expecting a new Guardian piece this week, having believed the Post had already published as much as it wanted to expose. What a surprise to wake up this morning and find a new Snowden revelation, but, this time, coming from the WaPo. Curious.
Fascinating that the President goes in front of the cameras to essentially brag that there’s nothing to see here because the publicly-known information didn’t provide evidence of actual misuse or wrongful searches of the vast data files — only to have these most recent releases confirm exactly such conduct and on a broad scale. EW, your parsing is once again incredible, but you don’t need to offer the NSA cover by apologizing for a math error — just wait for it, the NSA will try the “we’re only human” excuse real soon.
I’d much prefer to hear Obama and/or his minions try a Jeff Goldblum upon being confronted with the obvious duplicity of their secretizing actions, not only denying the existence and/or refusing to disclose but including even sanitizing those minimal records actually reported to the rubber-stamp non-adversarial “review” of FISA Court or the placebo procedures of “congressional oversight”: http://www.youtube.com/watch?v=AeDhiMtUA2I
I hope Leno and Letterman have a field day. And that Congress doesn’t avert its eyes to just how fundamentally dishonest this kabuki has been. Snowden must get a Presidential Medal of Freedom for his actions once Obama’s thought police get reined in.
According to the Washington Post from June 15th in their story on metadata:
“Two of the four collection programs, one each for telephony and the Internet, process trillions of “metadata” records for storage and analysis in systems called MAINWAY and MARINA, respectively. Metadata includes highly revealing information about the times, places, devices and participants in electronic communication, but not its contents. The bulk collection of telephone call records from Verizon Business Services, disclosed this month by the British newspaper the Guardian, is one source of raw intelligence for MAINWAY.”
MAINWAY is for telephony metadata. MARINA is for internet metadata.
Maybe I’m missing something, but if the error rate continued at the same rate for the next three quarters, wouldn’t it still be 8%? Not following how it would become cumulative, since the total number of queries (denominator) will also be increased.
Seriously, you have this wrong, and Marc Armbinder had it wrong. It has been established from the Washington Post reporting on this from the classified documents as to what MARINA has in it. They also had it in the annotations on the additional slides they published (beyond earlier PRISM slides by both the Post and the Guardian).
You are off in the wrong direction with this. Really.
@Kris: No. Because I used the 300 number which represents the entire year’s identifiers queried. So if the IDs were spread out over the year (they probably weren’t) there might be 75 queries a quarter.
So think 24 errors in 75 queries.
The core problem is that these databases are collected in the first place with a “if we don’t look at it, then we don’t have a 4th Amendment problem” approach. Sure, police sometimes break down the wrong door even if they have to get a search warrant, but that happens far fewer times than database query errors are made.
@Mindrayge: If Ambinder is wrong (I know WaPo reported this–I did too based on their reporting), it means that 1) they kept the Internet metadata going after it was supposedly ended in 2011 and 2) the Internet metadata suffers from the same problem the telephone one does. It also means that they’ve never made an error with the phone database (Mainway doesn’t show up at all) even though they acknowledge that they do.
I’m not sure you’re right for two reasons. First, bc Ambinder had by the point both were written, written far more on this, and bc the NSA’s Compliance guy seems to admit there is a problem with the phone stuff.
But I will try to sort that through.
@Mindrayge: Though I suppose if WaPo was right it’d be far more interesting, as Internet metadata is more intrusive.
@Mindrayge: I’ve adjusted the post. Thanks.
@emptywheel: You are welcome. The most important thing with all of this is that we keep what we know to be true (well, at least true at the time of the existence of any given document).
It is hard enough to keep everything we do know to be true straight because of all the obfuscation built into the way Intelligence programs are setup.
I left in another comment on an earlier story you had that I found the fact that both PINWHALE and MARINA being shown as systems was interesting considering that the e-mail collection allegedly ended. But, like anything else it may be that the program that was ended was UPSTREAM or part of it. So something is not as many of us might have surmised.
Trying to unravel this isn’t easy. I have made enough mistakes with this already.
@Mindrayge: I think PINWALE has always been abt email content, right? That hasn’t ended at all.
What isn’t clear (bc the govt hasn’t talked about the Internet side of it) is whether MARINA had just USP Internet metadata or everyone’s. If the former, then I am curious why they were still using it in January 2012. But they may just intend to age off that data, not end it outright. Which would be pretty outrageous.