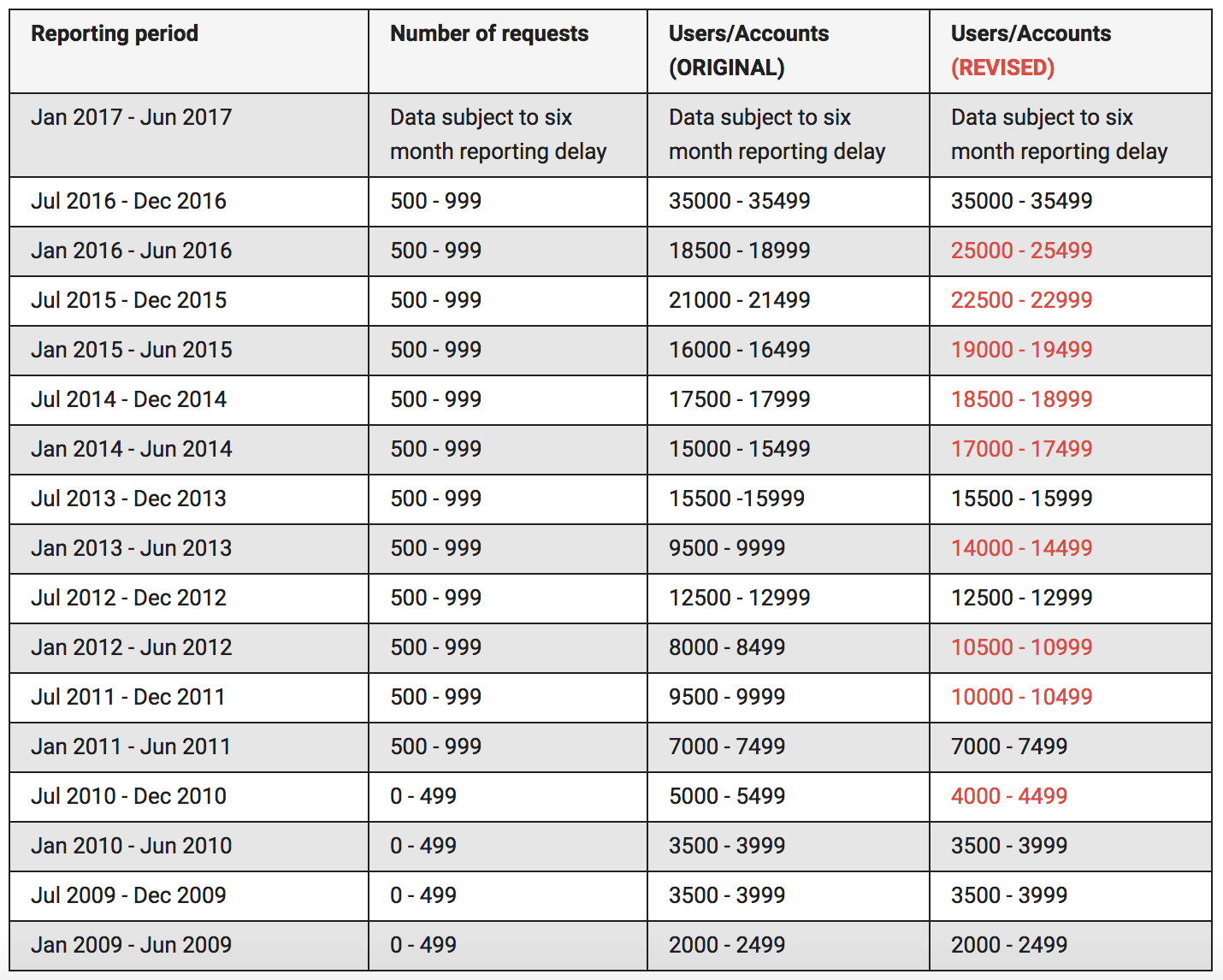
Three Things: Goodbye to the Once and Former Shitty Crustpunk Bar
[NB: As always, check the byline. /~Rayne]
Social media sites can be like your favorite watering hole, whether a blog, a forum, a platform like Orkut. You find one you’re comfortable hanging around because of content, and then you stay longer if you like the regulars who are likewise attracted to the content.
You get to know the regulars’ names after becoming familiar with the dynamics of the digital neighborhood. After a while you realize you’re a regular too – you’ve gotten to know this person has kids, that person has a beloved pet, yet another has a quirky habit manifest in the way they comment.
They get to know you and call you by your name as if you were Norm entering that Boston pub called Cheers.
Site moderators get to know you, too, may cut you a little slack if you’ve been there long enough and paid your dues to the community by making your own form of contribution with credible comment material and respectful interaction.
With some investment getting yourself situated for optimum comfort, it’s easy. Everything just comes to you — the bartender now knows exactly what to serve you.
All of this is incredibly important to people who are marginalized offline. The digital neighborhood can be a lifeline of sanity, a place where they can escape the oppressive crap of the real world. They can join the community through a lingua franca within their circle of safety. They don’t have to burn any more precious energy to obtain a measure of peace.
Safety borne of familiarity, regularity, and connection, of a cultivated common culture — that’s what the digital refugees who are fleeing Twitter miss, that’s what they’re seeking.
It’s not at all easy to replace. It also feels like personal and social loss to leave it.
Except the refugees didn’t leave it. It left them.
~ 3 ~
A couple years ago there was a really great thread at Twitter in response to comments made about the far right’s weaponization of free speech.
We’ve seen the weaponization in action in many ways – the white nationalist Nazi-types terrorizing Charlottesville with tiki torches while exercising their free speech, ultimately resulting in the death of a young woman crushed by a white nationalist expressing himself with his car.
Cosplay Nazi-lite lighting smoke bombs during a rally without a permit on the National Mall, or planning to disrupt a Pride parade again in cosplay.
Disrupting community events at libraries, terrorizing families enjoying themselves.
Or the January 6 insurrectionists storming the U.S. Capitol expressing their anger as they laid bombs the night before, breached barriers, assaulted police, shat on the floor, stole equipment while hunting for the House Speaker and the Vice President in order to kill them. Multiple people died as a result of the insurrection.
Anyhow, this chap at Twitter noted the point at which this weaponization of free speech should be addressed to prevent the predictable overreach into violence, when Popper’s Paradox is optimally preempted.
The venue needs to deal with the hate speech as soon as it arrives with its hair neatly combed wearing a button down with an insignia-covered tie. Cut it off in the whitewashed alt-right larval form; grab the club and set on on the bar top long before the Nazi must be punched. That’s when the effort is most effective; that’s when you can still fight and eliminate the emerging Nazis.
Unfortunately, Elon Musk figured out how to get inside this OODA loop.
He bought the bar. He was simply faster at doing this than Paul Singer was back in 2019.
And now the once-beloved shitty crustpunk bar which many of us could comfortably call home is now a goddamned Nazi pub.
The longer you stay there, the more that shit rubs off on you: you’re one of the Nazi watering hole’s patrons.
You’re a Nazi by association.
~ 2 ~
Jack Dorsey is a crypto Nazi. He’s been encouraging Musk for some time, and now he’s nudging him to take all remaining restraints off the Nazis Musk has already freed, including insurrectionists like Roger Stone. “[M]ake everything public now,” which will allow right-wing propagandists to run amok and distort past moderation decisions.
The way Twitter responded to Trump’s racist crap back when Dorsey was at the helm should have been clue enough; the donation Twitter made to the ACLU was just whitewash, the few hundred thousand a feint when Musk would spend billions to upend the entire place to free his Nazi fanbois’ speech.
Dorsey tried to play both sides but it was ultimately easier to let his buddy Musk strip away the veil. Or hood, if you’d prefer.
Bari Weiss is a Nazi apologist who thinks she can escape what Nazis do by being their handmaid, carrying Nazis’ water, chopping their wood for them.
All the Musk fanbois who are Oh-My-God-Twitter-Moderated, amplified in turn by Fox News in the wake of Musk euphemistically ‘exiting’ Twitter’s counsel? Nazis.
And of course there are the Nazis Musk let back in the bar, putting out the Welcome mat for them.
They’re all hanging at the Nazi bar Musk bought in order to make sure Nazis had a cozy place to call home because Gab, Parler, and Truth Social don’t have the commercial cachet to realistically achieve any level of social and economic success.
The financiers who either bought stock or loaned Musk money are likewise good with Nazism. It’s not a stretch to see how three Middle Eastern fossil fuel producing countries might want to destabilize the U.S. by normalizing Nazis in American right-wing culture.
This normalization which heightens internal conflict is to them not a failure.
So long as the American left and center are preoccupied with fighting Nazis, they’ll have less wattage to undermine stultifying fossil fuels to the benefit of alternative energy development.
No idea what the hell Oracle’s CEO Larry Ellison was thinking by loaning Musk money to buy Twitter. We can only rely on first principles and allow his actions to convey exactly what they look like: Ellison wanted a chunk of Nazi bar action.
That goes for all the other investors who loaned Musk money for Twitter.
Remember that social success may mean their ideas as noxious as they are gain what has been a mainstream platform used by this country’s largest media outlets — they are legitimized by proximity.
Remember that economic success may mean benefits other than those obtained by Twitter’s profitability. Like stifling discussion about alternatives to oil. Or disrupting conversations about open source, open data, open systems in the case of a proprietary database corporation’s CEO. Or thwarting changes to tax code which may affect billionaires by throttling communications by elected representatives who’d like to pass a tax increase on the 1%.
$44 billion for a Nazi bar might be a bargain.
~ 1 ~
This is when it gets – and already has been – dicey for advertisers.
Because they’re buying ad space from a Nazi bar, to be shown in a space where their brands appear cheek-and-jowl with Nazis.
The back and forth between Musk and Apple about Apple’s ad buys shouldn’t fool anyone. Apple doesn’t want to leave Nazi money on the table.
I say this with great disgust and a letter to the board of directors because I own Apple stock and the cost to buy Twitter would have been chump change to Apple.
It would have been more valuable to have access to a big chunk of the Android market’s users for advertising purposes while preventing damage to Apple’s brand if Apple had stepped up this past March after Musk’s stake in Twitter became public. Just whip out some cash and cut off the incipient Nazi bar.
But no, Apple fucked up.
Instead of making a values-based statement about its products and service the way they would have in the past, they’ve remained silent too long as Musk taunted them about free speech and nagged them about advertising buys.
What’s really even more egregious: while Musk is trash talking Apple and Apple responds in a way totally unlike one of the wealthiest and most creative on earth should, Musk is using Apple and refusing to compensate the corporation for it.
He just jacked up from $8 to $11 a month the price of Twitter Blue, the subscription service with verification to be available only to Apple iOS users, so that he passes on the fee Apple charges for listing in its app store.
In other words, Musk expects Apple to validate every Twitter Blue account by virtue of being an iPhone or iPad user with access to the Apple app store.
And he’s not going to pay Apple one goddamned cent for this validation service.
Meanwhile, Apple will continue to look Nazi-adjacent in Musk’s Nazi bar.
I hate that I’m going to trash my own retirement account saying this; I have a big chunk of my portfolio in Apple stock.
But I hate even more that Apple — which could have afforded to buy Twitter without going to other lenders as Musk did — is fucking up so badly and torching its brand by advertising in a Nazi bar and allowing a Nazi bar to profit off its hard work.
If Google ever figures out how to do microblogging, they may yet eat Apple’s lunch if they can stay clear of the Nazi bar and avoid Musk’s predatory moochery.
~ 0 ~
Yeah, I know — people I know, care about, and even in some cases love are still using Twitter.
You don’t need to know any longer what it was like in the 1930s before Kristallnacht, before the Reichstag fire. This is what it looked like, all the rationalizations, all the denialism, all the lingering doubts about whether it’s better to remain and hold the space, stay and fight, or walk away even as people fled Germany for safety.
The fight’s done, though.
Think about it: what happens to you when you get into a fight inside a Nazi bar?
There are other bars. Some of them are shitty, some crusty, some punk. One of them may only need you to make it a shitty crustpunk bar.
Maybe even one with a surly bartender who clearly hates you but still keeps a hand on their bat for Nazis.